Ai Empower Labs
Introduction
Welcome to Studio by AI Empower Labs documentation! We are thrilled to offer developers around the world access to our cutting-edge artificial intelligence technology and semantic search. Our API is designed to empower your applications with state-of-the-art AI capabilities, including but not limited to natural language processing, audio transcription, embedding, and predictive analytics.
Our mission is to make AI technology accessible and easy to integrate, enabling you to enhance your applications, improve user experiences, and innovate in your field. Whether you're building complex systems, developing mobile apps, or creating web services, our API provides you with the tools you need to incorporate AI functionalities seamlessly.
Support and Feedback We are committed to providing exceptional support to our developer community. If you have any questions, encounter any issues, or have feedback on how we can improve our API, please don't hesitate to contact our support team @ support@AIEmpowerLabs.com.
Terms of Use Please review our terms of use and privacy policy before integrating our API into your application. By using our API, you agree to comply with these terms.
What is AI Empower Labs providing to our customers
AI Empower Labs have developed a system for customers to create their own versions of a Chat GPT like AI system based on Large Language Model technology. This concept is often called a Generative AI System.
A Complete LLM and RAG system
Retrieval-Augmented Generation (RAG) combines the powers of pre-trained language models with a retrieval system to enhance the generation of text. This method retrieves documents relevant to a query and then uses this contextual information to generate responses. It's especially useful in tasks where having additional context or external knowledge can significantly improve the quality or accuracy of the output, such as in question answering, content creation, and more complex conversational AI systems.
AI Empower Labs have made a complete set of server containers so that customers can run both an LLM to generate replies, a Semantic search tool to find relevant information and append that to a RAG model for the LLM to be able to answer customer specific questions in an effective way.
In the system we also added a number of related technologies like speech-to-text, named entity recognition, Keyword extraction and Semantic similarity. speech to text makes is easy to apply AI in voice based interactions and the others are available to customer to use to created complete AI systems that can provide data for customer to do remote process calls and business transactions as part of an AI system.
We hoope you enjoy our products!
Getting started
AI Empower Labs provide servers are easy to install. To be able to try our services customers have two choices:
- Use the shared test instance of the Studio and the shared public test APIs in OpenAPI or Swagger.
- Download AI Empower Labs free to use containers and run locally in your data center.
What is in the package
Ai Empower Labs servers contain a set of powerful and easy to use Gen AI features.

Getting started with the Public shared test version
You can access the public shared test version online now by using theshared test instance of the Studio and the shared public test APIs in OpenAPI or Swagger.
Here can also upload your own process descritions, sound files, documents to the test instance to verify the performance or the services
Getting started with the local downloaded version
Basicly three steps are needed:
- Download the containers files
- Install them
- Access the services on the local default ports
Installation
the installation depends on your aspirations. If you just want to download Ai Empower Labs and start development you can follow the first simple docker based steps on our installation guide.
Installation instructions are available on GitHub. Please visit Ai Empower Labs GitHub Studio library here
Studio is Ai Empower Labs open source sample application that uses the Ai compontents developed by us.
Make sure you have a hosting environment ready to run the containers in.
If you are a Kubernetes user you should be familiar with defining deployments based on containers yourself. Currently we do not offer helm charts. We will do this based on customer request. If you have an interest in obtaining our sofware as helm charts please contact us through our web page
If you just want to test and get started, use Docker as in the example below.
Installation guide
The script at GitHub is sufficient, but here are some explanatory installation instructions
Pre-requisites
Make sure you are running an Intel or AMD based CPU. the default compiled packages will not run properly on Apple CPUs.
####Install docker and docker compose. Make sure you have a container hosting environment available. In the simplest possible approach you can just download Docker. The you need to install docker compose on your hosting server.
Clone our repository
Then you should be good to go:-)
- First clone the repository.
git clone https://github.com/AI-Empower-Labs/Studio cd ./Studio/docker/minimum
- Then, open a terminal windows in your server and run the commands:
Pull to get the latest versions:
docker compose pull
This will start a download of the containers to your server:
 the download will fill ca 30 GB on your disks so please make sure you have enough space available.
the download will fill ca 30 GB on your disks so please make sure you have enough space available.
Container files with descriptions
| Container | Size | Comment | |--------------- |------- |----------------------------------------------------------------------------------------- | | translation | 6,3GB | The translation related services | | postgres | | For customer not already having a suitable database, a postgress container | | embedding | | the embedding services, converting ingested information to embeddings for use with LLMs | | transcription | | a container running the speech to text related services | | llama3 10 | 5GB | the default Large Language Model (LLM) container | | host | 84MB | the mother container for the studio applications |
When the Pull is done, start the docker containers:
docker compose up
After this you should be able to see the containers in your docker admin ui running. See details on the GITHub page for how to start containers as back ground services
To stop all services:
docker compose down
For more details see your GitHub Studio application page.
The default downloaded version will be a free version with the limitaion of one request per second. If you want to increase to a higher performance opackage, and/or to arrange support, please reach out to us through our home page.
Installation in a production environment
For installation in a production enviroment your should consider the inforation under running with GPU support and the detailed instruction on how to install licenses below.
###Running with GPU support For running and tuning the servers see the detailed installation guide on GitHub and in the GPU section.
Here a detailed setup on how to tune your sofware for GPU performance are provided
Install licenses
In the GitHub studio pages detailed instructions are availale on how to configure licenses.
Features
Generative AI or Gen AI
When reading about our features make sure you understand what a Gen AI system is and how it is built up first
Background
A Generative AI system is a type of artificial intelligence designed to create content. Unlike discriminative models that classify input data into categories, generative models can generate new data instances that resemble the training data. These systems can produce a wide range of outputs, including text, images, music, voice, and even synthetic data for training other AI models. Here's an overview of its key aspects:
How it Works: Generative AI systems often use advanced machine learning techniques such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformer models. In a GAN, for example, two networks are trained simultaneously: a generative network that creates data and a discriminative network that evaluates it. The generative network learns to produce more authentic outputs through this competition.
Applications: At AI Empower Labs we are currently focused on:
- Text Generation: Creating realistic and coherent text for articles, stories, code, or conversational agents.
- Text to speech and speech to text: Using AI to extract text from voice data
RAG
Retrieval-Augmented Generation (RAG) combines the powers of pre-trained language models with a retrieval system to enhance the generation of text. This method retrieves documents relevant to a query and then uses this contextual information to generate responses. It's especially useful in tasks where having additional context or external knowledge can significantly improve the quality or accuracy of the output, such as in question answering, content creation, and more complex conversational AI systems.
###Here's a breakdown of RAG features:
- Retrieval Component: At its core, RAG uses a retrieval system (like a search engine) to find documents that are relevant to the input query. This retrieval is typically performed using a dense vector space, where both queries and documents are embedded into vectors in a high-dimensional space. The system then searches for the nearest document vectors to the query vector.
- Augmentation of Pre-trained Models: RAG leverages pre-trained language models (like those from the GPT or BERT families) by feeding the retrieved documents into these models as additional context. This way, the generation is informed by both the input query and the retrieved documents, allowing for responses that are not only contextually relevant but also enriched with external knowledge.
- Flexible Integration: The RAG architecture can be integrated with different types of language models and retrieval mechanisms, making it highly versatile. Whether you're using a transformer-based model for generation or a different vector space model for retrieval, RAG can accommodate various setups.
- Improved Accuracy and Relevance: By incorporating external information, RAG models can produce more accurate and relevant responses, especially for questions or tasks that require specific knowledge not contained within the pre-trained model itself.
- Scalability and Efficiency: Despite its complex capabilities, RAG is designed to be scalable and efficient. It uses techniques like batched retrieval and caching to minimize the computational overhead of accessing external documents.
- End-to-End Training: RAG models can be fine-tuned end-to-end, allowing the retrieval and generation components to be optimized jointly. This leads to better alignment between the retrieved documents and the generated text, improving overall performance.
RAG represents a significant step forward in the field of natural language processing and generation, offering a way to create more informed, knowledgeable, and contextually relevant AI systems.
On-prem LLMs (Large Language Models)
A Large Language Model (LLM), like the one you're interacting with now, is an advanced artificial intelligence system designed to understand, generate, and interact with human language at a large scale. These models are based on a type of neural network architecture known as Transformer, which allows them to process and predict sequences of text efficiently. Here are some key points about Large Language Models:
-
Training Data and Process: LLMs are trained on vast datasets consisting of text from the internet, books, articles, and other language sources. The training process involves teaching the model to predict the next word in a sentence given the words that precede it. Through this, the model learns language patterns, grammar, semantics, and even some knowledge about the world.
-
Capabilities: Once trained, these models can perform a wide range of language-related tasks without needing task-specific training. This includes answering questions, writing essays, translating languages, summarizing texts, generating code, and engaging in conversation. Their flexibility makes them valuable tools in fields ranging from customer service and education to software development.
-
Examples: OpenAI's GPT (Generative Pre-trained Transformer) series, including GPT-3 and its successors, are prominent examples of Large Language Models. There are also other models like BERT (Bidirectional Encoder Representations from Transformers) by Google, which is optimized for understanding the context of words in search queries.
-
Challenges and Ethical Considerations: While LLMs are powerful, they also present challenges such as potential biases in the training data, privacy concerns, the propagation of misinformation, and the need for significant computational resources for training and deployment. Ethical use and ongoing research into mitigating these issues are crucial aspects of the development and deployment of these models.
-
Evolution and Future: LLMs continue to evolve, becoming more sophisticated with each iteration. This includes improvements in understanding context, generating more coherent and contextually relevant responses, and reducing biases. Future developments are likely to focus on making these models more efficient, ethical, and capable of understanding and generating language even more like a human.
Supported LLMs
Ai Empowerlabs recommends running one one of these OpenSource LLM's when using self hosted LLM's
| Model / Card |
|---|
| Mixtral-8x7B-v0.1 |
| Mistral |
| Llama2 |
| Phi2 |
Or variants here of where models are further finetuned, depending of use case and hardware options available. However Ai Empowerlabs can consume - almost - any OpenSource model as well as any OpenAI compatible model, and any of these in parallel. We have made anvancements on how to best execute LLM in a production computing architecture to get the most performance, stability and efficiency in your data centers. Ai Empower Labs are focuses on creating possibilities for customers to run Gen AI containers safe, trustable, cost efficient and with as little as possible devops team as possible in your organisation.
Semantic Search
Semantic search in the context of Large Language models and RAG can be describes as these parts:
Retriever: This component is responsible for fetching relevant documents or passages from a large dataset (like Wikipedia) based on the query's semantic content. It doesn't just look for exact matches of query terms but tries to understand the query's intent and context. Techniques like Dense Vector Search are often used, where queries and documents are embedded into high-dimensional vectors that represent their meanings.
Answer Generator: This part, typically an LLM, takes the context provided by the retriever and generates a coherent and contextually appropriate answer. The generator can infer and synthesize information from the retrieved documents, leveraging its own trained understanding of language and the world.
LLMs, through their vast training on diverse textual data, inherently support semantic search by understanding and generating responses based on the meaning of the text rather than just the presence of specific words or phrases. When used in a semantic search:
Understanding Context: They can understand the nuanced meaning of queries, including idiomatic expressions, synonyms, and related concepts, allowing them to retrieve or generate more accurate and relevant responses.
Generating Responses: They can provide answers that are not just based on the most common responses but are tailored to the specific context and meaning of the query, often synthesizing information from various parts of their training data.
In essence, semantic search in the context of RAG and LLMs is about understanding and responding to queries in a way that mimics human-like comprehension, leveraging both the vast information available in external datasets and the deep, nuanced understanding of language encoded in the models. This approach enables more accurate, relevant, and context-aware answers to complex queries.
Ai Empower labs have created a powerful multilanguage semantic search engine capable of matching indexed data cross langugaes! And our innovative container and execution engine makes it much more efficient to run than a standard python based open source script you can download of the internet. Here the real power liest in our offering. No need to spend thousands of Euros at Pinecone or similar services. Runs stable, safe anf efficient in your own data center
Embeddings
Embeddings is a key feature to secure performance in the Gen AI system. When running towards major cloud vendors like Microsoft and OpenAI you will often experience slow responses in the API, often creating a poor and boring user experience.
At AI Empowerlabs we have invested in optimising how your avaiable computing power can be utilised for cost efficient performance.
In the context of artificial intelligence and natural language processing (NLP), an embedding is a representation of data, usually text, in a form that computers can understand and process efficiently. Essentially, embeddings convert words, phrases, sentences, or even entire documents into vectors of real numbers. These vectors capture semantic meanings, relationships, and the context in which words or phrases appear, enabling machines to understand and perform tasks with natural language.
Key Points About Embeddings:
-
Dimensionality: Embeddings are typically represented as high-dimensional vectors (often hundreds or thousands of dimensions) in a continuous vector space. Despite the high dimensionality, embeddings are designed to be efficient for computers to process.
-
Semantic Similarity: Words or phrases that are semantically similar tend to be closer to each other in the embedding space. This allows AI models to understand synonyms, context, and even nuances of language.
-
Usage in AI Models: Embeddings are foundational in various NLP tasks and models, including sentiment analysis, text classification, machine translation, and more. They allow models to process text data and perform tasks that require understanding of natural language.
-
Types of Embeddings:
- Word Embeddings: Represent individual words or tokens. Examples include Word2Vec, GloVe, and FastText.
- Sentence or Phrase Embeddings: Represent larger chunks of text, capturing the meaning of phrases or entire sentences.
- Document Embeddings: Represent whole documents, capturing the overall topic or sentiment.
-
Training Embeddings: Embeddings can be pre-trained on large text corpora and then used in specific tasks, or they can be trained from scratch as part of a specific AI model's training process.
Example:
Consider the words "king," "queen," "man," and "woman." In a well-trained embedding space, the vector representing "king" minus the vector representing "man" would be similar to the vector representing "queen" minus the vector representing "woman." This illustrates how embeddings capture not just word meanings but relationships between words.
Embeddings are a critical technology in the field of AI, enabling models to deal with the complexity and richness of human language by translating it into a mathematical form that algorithms can work with effectively.
Named Entity Recognition
Named Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. NER is a fundamental step for a range of natural language processing (NLP) tasks like question answering, text summarization, and relationship extraction, providing a deeper understanding of the content of the text by highlighting its key elements.
Here's a closer look at its components and applications:
Named Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. NER is a fundamental step for a range of natural language processing (NLP) tasks like question answering, text summarization, and relationship extraction, providing a deeper understanding of the content of the text by highlighting its key elements.
Here's a closer look at its components and applications:
Components of NER
- Identification of Named Entities: The primary step is to identify the boundaries of named entities in text. This involves distinguishing between general words and those that represent specific entities.
- Classification of Entities: After identifying the entities, the next step is to classify them into predefined categories such as person names, organizations, locations, dates, etc.
- Contextual Analysis: NER systems often require an understanding of the context in which an entity is mentioned to accurately classify it. For example, distinguishing between "Jordan" the country and "Jordan" a person's name.
Techniques Used in NER
- Rule-based Approaches: These rely on handcrafted rules based on linguistic patterns. For instance, capitalization might be used to identify proper names, while patterns in the text can help identify dates or locations.
- Statistical Models: These include machine learning models that learn from annotated training data. Traditional models like Hidden Markov Models (HMMs), Decision Trees, and Support Vector Machines (SVMs) have been used for NER tasks.
- Deep Learning Models: More recently, deep learning approaches, especially those based on Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers, have been employed for NER, often achieving superior results by learning complex patterns from large datasets.
Applications of NER
- Information Retrieval: Improving search algorithms by focusing on entities rather than mere keywords.
- Content Recommendation: Recommending articles, products, or services based on the entities mentioned in content a user has previously shown interest in.
- Customer Support: Automatically identifying important information in customer queries to assist in quicker resolution.
- Compliance Monitoring: Identifying sensitive or regulated information in communications or documents.
- Knowledge Graph Construction: Extracting entities and their relationships to build knowledge bases for various domains.
NER is a crucial component in the toolkit of natural language processing, enabling machines to understand and process human languages in a way that is meaningful and useful for a wide array of applications.
What is Semantic Similarity and the relevancy for this in Generative AI
Semantic similarity in the context of Generative AI (Gen AI) refers to the measure of likeness between two pieces of text based on the meaning they convey, rather than their superficial characteristics or syntactic similarity. This concept is crucial in various natural language processing (NLP) tasks and applications within Generative AI, enabling these systems to understand, generate, and manipulate language in ways that align more closely with human understanding and use of language.
How it Works
- Vector Space Models: One common approach to assess semantic similarity involves representing text as vectors in a high-dimensional space (using techniques such as TF-IDF, word embeddings like Word2Vec, GloVe, or contextual embeddings from models like BERT). The semantic similarity between texts can then be quantified using distance or similarity metrics (e.g., cosine similarity) in this space, where closer vectors represent more semantically similar content.
- Transformer Models: Modern Generative AI systems, especially those based on transformer architectures, inherently learn to encode semantic information in their representations. These models, through self-attention mechanisms, are adept at capturing nuanced semantic relationships within and across texts, facilitating a deeper understanding of similarity based on context and meaning rather than just keyword matching.
Applications
- Text Generation: Semantic similarity measures can guide the generation of text that is contextually relevant and coherent with given input text, enhancing the quality of outputs in applications like chatbots, content creation tools, and summarization systems.
- Content Recommendation: By assessing the semantic similarity between documents, articles, or user queries and content in a database, systems can provide more relevant and meaningful recommendations to users.
- Information Retrieval: Enhancing search engines and databases to return results that are semantically relevant to the query, even if the exact words are not used, leading to more effective and intuitive search experiences.
- Question Answering and Conversational AI: Semantic similarity allows for the matching of user queries to potential answers or relevant information in a knowledge base, even when queries are phrased in varied ways, improving the performance of QA systems and conversational agents.
- Document Clustering and Classification: Grouping or classifying documents based on the semantic content enables more efficient information management and retrieval, useful in areas like legal document analysis, academic research, and content management systems.
Semantic similarity is a foundational concept in Generative AI, enabling these systems to interact with and process human language in a way that is both deeply meaningful and contextually nuanced. This capability is integral to creating AI that can effectively understand, communicate with, and serve the needs of humans in a wide range of applications.
AI Empowerlabs NER can be tested in studio. The apps will illustrate how you can use NER in API scenarios and is built on the provided APIs
Speech to text transcription
AI Empowerlabs include a powerful multilanguage Speech to text. Capable of transcrpting speech from multiple languages. We have enhanced and embeeded whisper based solution and added easy to use capabilities of integrating several streams into one text object.
Artificial Intelligence (AI) has significantly improved speech-to-text (STT) transcription technologies, making them more accurate, faster, and adaptable to various use cases and environments. Here are several key ways AI enhances speech-to-text transcriptions:
1. Increased Accuracy
- Contextual Understanding: AI algorithms can understand context and disambiguate words that sound similar but have different meanings based on their usage in a sentence. This context-aware transcription significantly reduces errors.
- Accent Recognition: AI models trained on diverse datasets can accurately transcribe speech from speakers with a wide range of accents, improving accessibility and user experience for a global audience.
2. Real-time Transcription
- AI enables real-time or near-real-time transcription, essential for live broadcasts, meetings, and customer service interactions. This immediate feedback is crucial for applications like live subtitling or real-time communication aids for the deaf and hard of hearing.
3. Learning and Adapting
- Continuous Learning: AI models can learn from their mistakes and adapt over time, improving accuracy with continued use. This learning process includes adapting to specific voices, terminologies, and even user corrections.
- Personalization: Speech-to-text systems can be personalized to recognize and accurately transcribe specific jargons, technical terms, or even user-specific colloquialisms, making them more effective for professional and industry-specific applications.
4. Noise Cancellation and Background Noise Management
- AI can distinguish between the speaker's voice and background noise, filtering out irrelevant sounds and focusing on the speech. This capability is particularly valuable in noisy environments, ensuring clear and accurate transcriptions.
5. Language and Dialect Support
- With AI, speech-to-text systems can support a broader range of languages and dialects, often underserved by traditional technologies. This inclusivity opens up technology access to more users worldwide.
6. Integration with Other AI Services
- Speech-to-text can be combined with other AI services like sentiment analysis, language translation, and chatbots to provide more comprehensive solutions. For example, transcribing customer service calls and analyzing them for sentiment can offer insights into customer satisfaction.
7. Cost-effectiveness and Scalability
- AI-driven systems can handle vast amounts of audio data efficiently, making speech-to-text services more cost-effective and scalable. This scalability allows for the transcription of large volumes of lectures, meetings, and media content that would be prohibitive with manual transcription services.
Future Directions
AI is also driving innovation in speech-to-text technologies through approaches like end-to-end deep learning models, which promise further improvements in accuracy, speed, and versatility. As AI technology continues to evolve, we can expect speech-to-text transcription to become even more integrated into our daily lives, enhancing accessibility, productivity, and communication.
Using the Gen AI prompt when interaction with Gen AI services in APIs or in the Studio apps
Prompt engineering is the process of designing and refining prompts that guide artificial intelligence (AI) models, like chatbots or image generators, to produce specific or desired outputs. This practice is especially relevant with models based on machine learning, including those trained on large datasets for natural language processing (NLP) or computer vision tasks. The goal is to communicate effectively with the AI, guiding it towards understanding the task at hand and generating accurate, relevant, or creative responses.
The skill in prompt engineering lies in how questions or commands are framed. The quality of the input significantly influences the quality of the output. This includes the choice of words, the structure of the prompt, the specificity of instructions, and the inclusion of any context or constraints that might help the model understand the request better.
Prompt engineering has become increasingly important with the rise of models like GPT (Generative Pre-trained Transformer) for text and DALL-E for images, where the ability to elicit precise or imaginative outputs from the model becomes a blend of art and science. It involves techniques like:
- Prompt Crafting: Writing clear, concise, and well-defined prompts that align closely with the task you want the AI to perform.
- Prompt Iteration: Experimenting with different formulations of a prompt to see which produces the best results.
- Zero-shot, Few-shot, and Many-shot Learning: Specifying the amount of guidance or examples provided to the AI. Zero-shot involves giving the AI a task without any examples, few-shot includes a few examples to guide the AI, and many-shot provides many examples to help the AI understand the context better.
- Chain of Thought Prompting: Providing a step-by-step explanation or reasoning path in the prompt to help the AI tackle more complex questions or tasks.
Effective prompt engineering can significantly enhance the performance of AI systems in various applications, such as content creation, data analysis, problem-solving, and customer service, making it a valuable skill in the AI and computer science fields.
Examples of prompt engineering commands
These examples will illustrate how different ways of asking or framing a question can lead to varied responses, showcasing the importance of clear and effective communication with AI systems.
1. Direct Command
- Basic Prompt: "Write a poem about the sea."
- Engineered Prompt: "Create a short, four-line poem in the style of a haiku about the peacefulness of the sea at sunset."
Explanation: The engineered prompt is more specific, not only requesting a poem about the sea but also specifying the style (haiku) and the theme (peacefulness at sunset), likely leading to a more focused and stylistically appropriate response.
2. Adding Context
- Basic Prompt: "Explain the theory of relativity."
- Engineered Prompt: "Explain the theory of relativity in simple terms for an 8-year-old, focusing on the concept of how fast things move through space and time."
Explanation: By adding context about the audience's age and focusing on key concepts, the engineered prompt guides the AI to tailor the complexity of its language and the aspects of the theory it discusses.
3. Request for Examples
- Basic Prompt: "What is machine learning?"
- Engineered Prompt: "What is machine learning? Provide three real-world examples of how it's used."
Explanation: This prompt not only asks for a definition but also explicitly requests examples, making the response more practical and illustrative.
4. Specifying Output Format
- Basic Prompt: "List of renewable energy sources."
- Engineered Prompt: "Generate a bullet-point list of five renewable energy sources, including a brief explanation for each."
Explanation: The engineered prompt specifies not only to list the sources but also to format the response as a bullet-point list with brief explanations, making the information more organized and digestible.
5. Encouraging Creativity
- Basic Prompt: "Story about a dragon."
- Engineered Prompt: "Write a captivating story about a friendly dragon who loves baking, set in a magical forest. Include dialogue and describe the setting vividly."
Explanation: The engineered prompt encourages creativity by adding details about the dragon's personality, setting, and including specific storytelling elements like dialogue and vivid descriptions.
6. Solving a Problem
- Basic Prompt: "How to fix a slow computer."
- Engineered Prompt: "List the top five reasons a computer might be running slowly and provide step-by-step solutions for each."
Explanation: This prompt not only asks for reasons behind a common problem but also guides the AI to structure the response in a helpful, step-by-step format, making it more actionable for the reader.
These examples illustrate the principle of prompt engineering: by carefully crafting your request, you can guide the AI to produce more precise, informative, or creative outputs. This is a crucial skill in fields that involve human-AI interaction, enhancing the effectiveness of AI tools for a wide range of applications.
Language Detection
Language detection is a small but powerful feature to be able to automate language handling in services build from AI Empower Labs containers. Being able to detect a language based on a short string of text makes it possible to create application that can handle communication on the language of the user types. Combined with the powerful tranlation services you are able to make sure that each system user can use one or more languages that they are most comfortable with, even if the indexed information in the RAG system and in the embedded LLMs are written in other languages
Translation
Translation is a powerful tool to be used in relation to providing data in the lanugage preferred by the user. Translation can also facilitate communication across languages between different users of the systems, both for voice and text
Studio introduction
AI Empower Labs Studio is an application designed for you to be able to create a grounded GenAI environment with RAG for your company
After you have downloade and installed the containers you are able to access th Studio over http
In the Studio web interface, you can add data to ground your gen AI system by uploading your own data, manage the added data, and split them into use case areas or indexes.
Studio is also a test tool to for you to test the uploaded data and tune usage of the data
Studio also contains a sample end-user-facing application supporting both written and voice based communcation. Grounded chat is a tool to test your grounded Gen AI system
You can also use Studio to compare LLMs with other LLMs find a good version for you, partly you can also use this ability to compate to verify that the products from AI Empower Labs work well for you! And performs well compared to Global Vendors
Studio use cases
LLM/Semantic Search
Supported LLMs
This list shows AI Empower Labs supported LLMs. Some of these are only cloud based and some are possible to download as containers from AI Empower Labs and install in your own solution.
The public ones can be used in some of the test applications of Studio to compare results between global vendors and AI Empower Labs on-prem versions.
Supported Embeddings
AI Empower Labs provide a number of embedding systems based on customer needs. We also provide test cases to a few public ones for customers to compare results and check the quality of AI Empower Labs services
Supported tokenizers
AI Empower Labs provide a number of tokenizers based on customer needs. We also provide test cases to a few public ones for customers to compare results and check the quality of AI Empower Labs services
Voice & Chat
 Voice & Chat Conversation tool is the main interface to the AI Empower Labs products. This tool makes it possible do conversations in text and voice format with the system provided by AI Empower Labs
Voice & Chat Conversation tool is the main interface to the AI Empower Labs products. This tool makes it possible do conversations in text and voice format with the system provided by AI Empower Labs
Here you can access the LLMs and the RAG system through an interface with either you voice or text as input. The results will be presented both in voice output and text output.
Using the APIs you can easily implement such a tool yourself. If you do not want to to code yourself you can offer your users to connect directly with the Studio API as provided by AI Empower Labs
To try the voice interface klick the SPEAK button and make sure the browser is allowed to use your microphone. When done speaking, click STOP and then ASK to trigger a response.
You can also use the Persona config to enter prompt commands using the keyboard. By default users can write in any lanugage and will receive the response in English. Ai Empower Labs can ingest documents in any language and search is across languages and matches very good. Normally one should spend some time adjusting the persona settings to fit your needs. A common thing to att is for example: "please follow the language of the user".
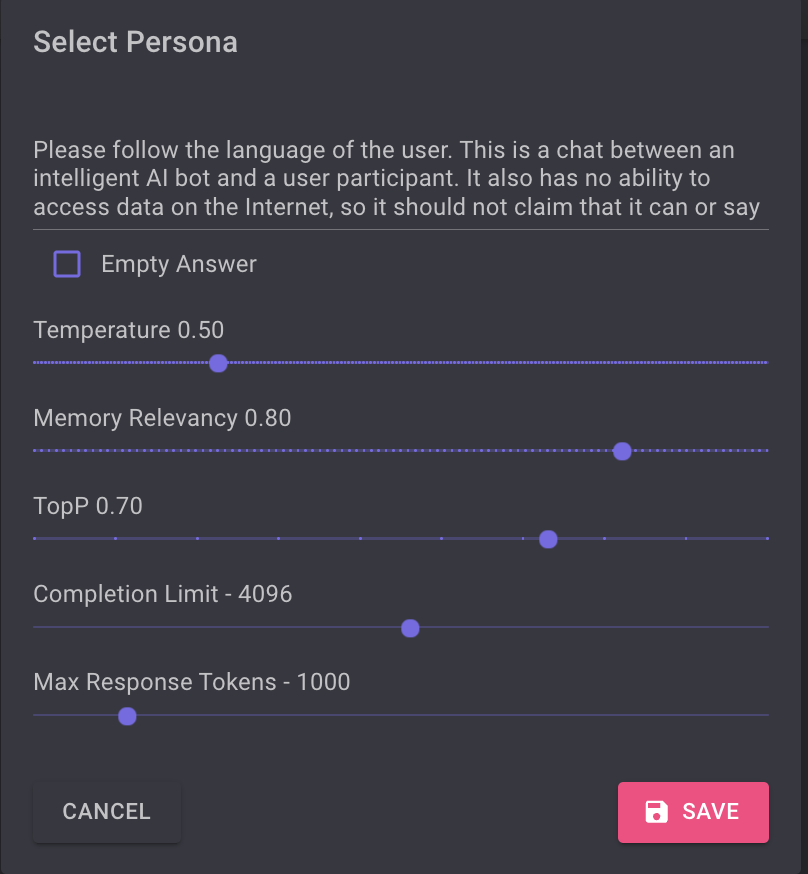
Other settings:
Temperature: a parameter used during the generation of text to control randomness and creativity, please reserch before you change this parameter.
Memory Relevance: How the model manages and utilizes its understanding or "memory" of the context within a conversation to generate relevant responses. In general do not change this setting before you have done some research related to the LLM you have choosen.
TopP: The term "top-p" (also known as "nucleus sampling") is a technique used in natural language processing for generating text by large language models (LLMs). It is an alternative to the more deterministic "top-k" sampling method and is designed to provide a balance between diversity and relevance in generated text.
Completion Limit: Completion limits are a critical aspect of designing interactions with LLMs, as they balance user expectations, system performance, and the practical limitations of technology. Research online for more details.
Max Response tokens: How many tokens are allowed in the response.
The responses to both text and voice input will coming in both text and voice format.
The virtual agent controls
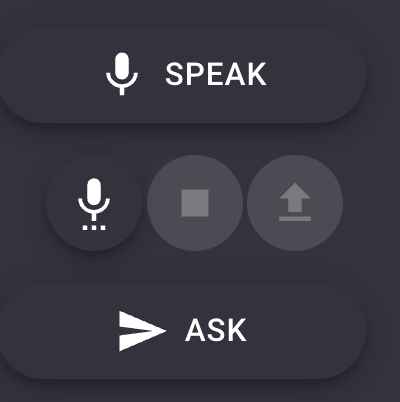
The Microphone icon is used to enable and disable voice. Here you can also change the settings for the syntized voice. This is useful if you wish to have replies in another language than the default English/UK.
The Stop icon is to stop the virtual assisten during a reply.
The Arrow Up/Eject icon is used to clear a context and start over.
The Ask button is used to trigger a processing of the text in the prompt.

To also add your own data as a source of knowledge for the virtual assistant you can use the "query index" selector.
Index Management
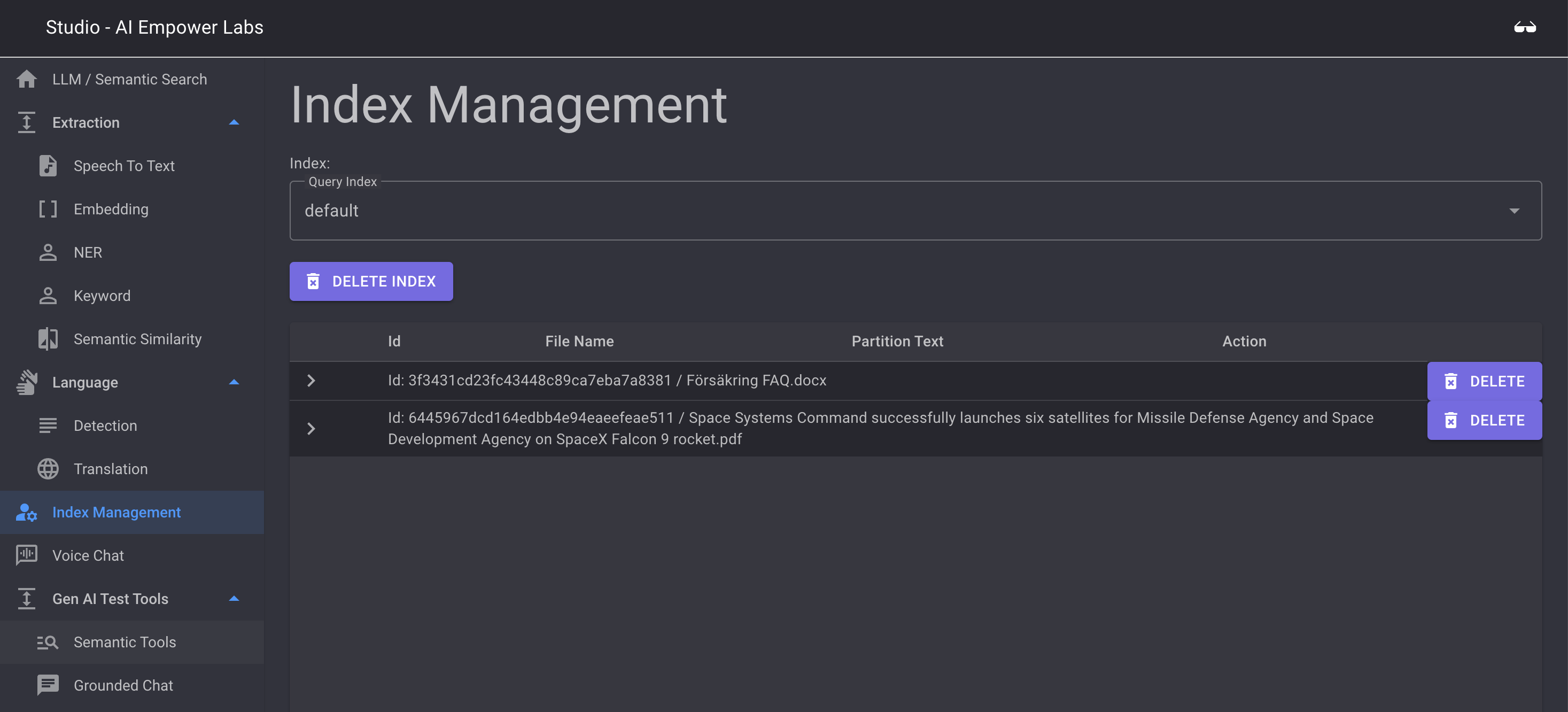 Index Management is where you can manage the indexes in the embedded data for your service. In this tool you are able to see what data is uploaded by your users and chat indexes this data is grouped by. You are also able to delete uploaded data
Index Management is where you can manage the indexes in the embedded data for your service. In this tool you are able to see what data is uploaded by your users and chat indexes this data is grouped by. You are also able to delete uploaded data
To add new indexes and upload data see Semantic Tools below.
Gen AI Test Tools
Semantic Query Tools & Add data filed
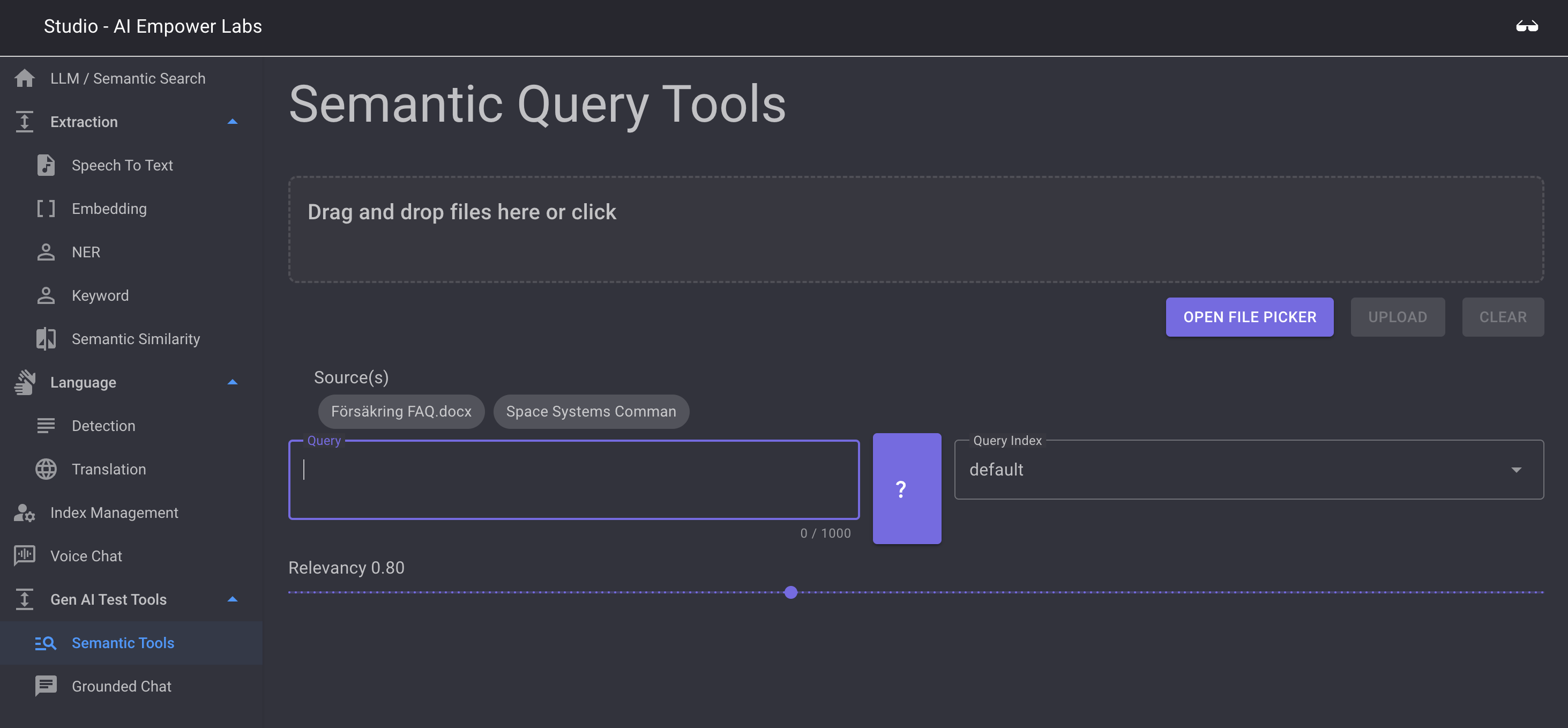 to upload new data to indexes and test this data you can use the Semantic Query tool. Here you can test running search queries towards the existing indexes and to upload more data to these indexes.
to upload new data to indexes and test this data you can use the Semantic Query tool. Here you can test running search queries towards the existing indexes and to upload more data to these indexes.
Drag files to the drop zone or click the OPEN FILE PICKER to add more data to your indexes
To test Semantic Search agains your uploaded files and indexes, select the index you wish to search against in the Query Index select fiels and then enter your prompt commands and the search string in the Query field, example:
When done klick on the ? to execute the semantic query

You can contol the minimum acuracy setting by moving the relevancy slider.
Below the slider you will se the Semantic Search results based on the index you choose.
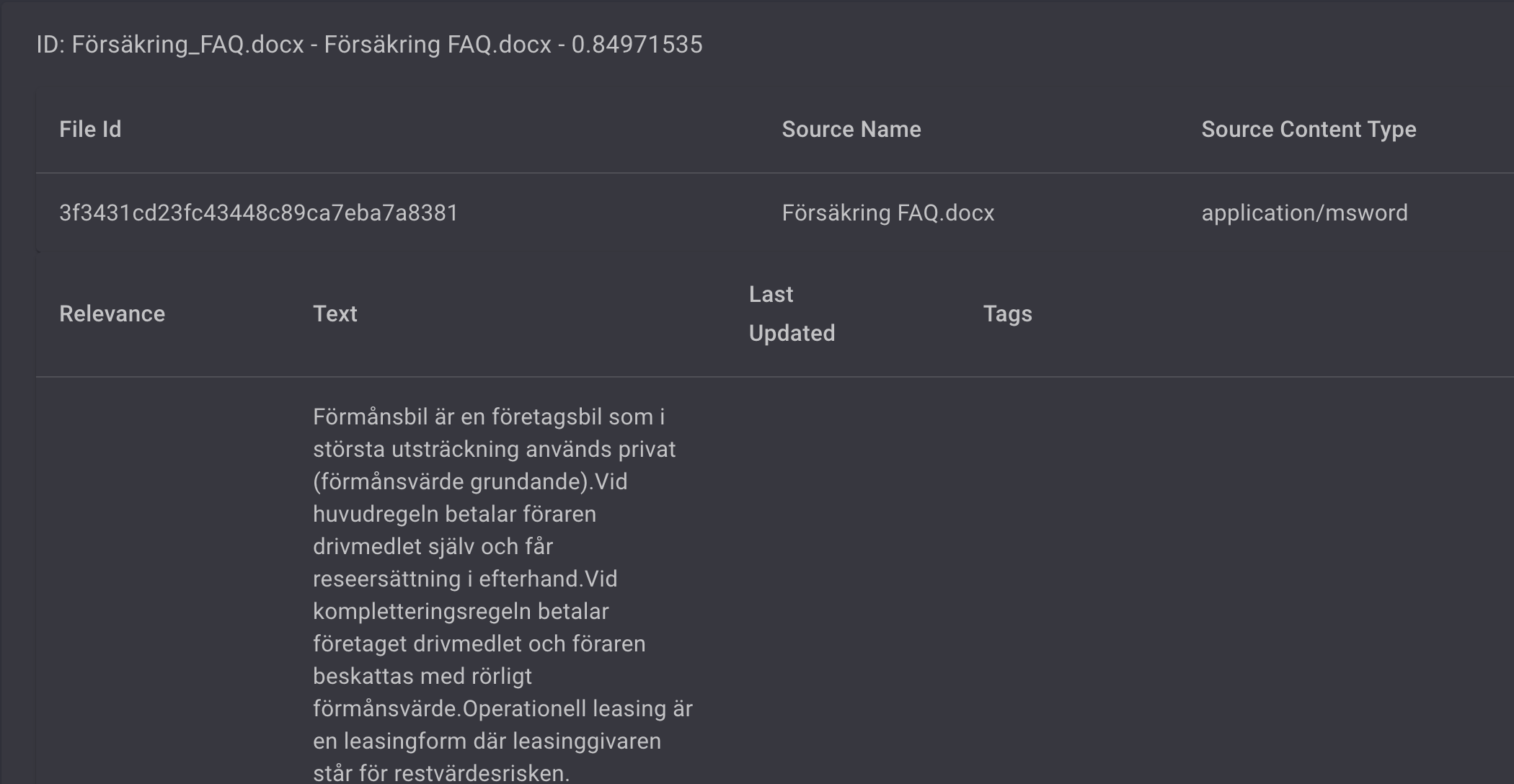
You can also klick the TAG CLOUD to see a wordcloud of related terms found inside the index.
Grounded Chat
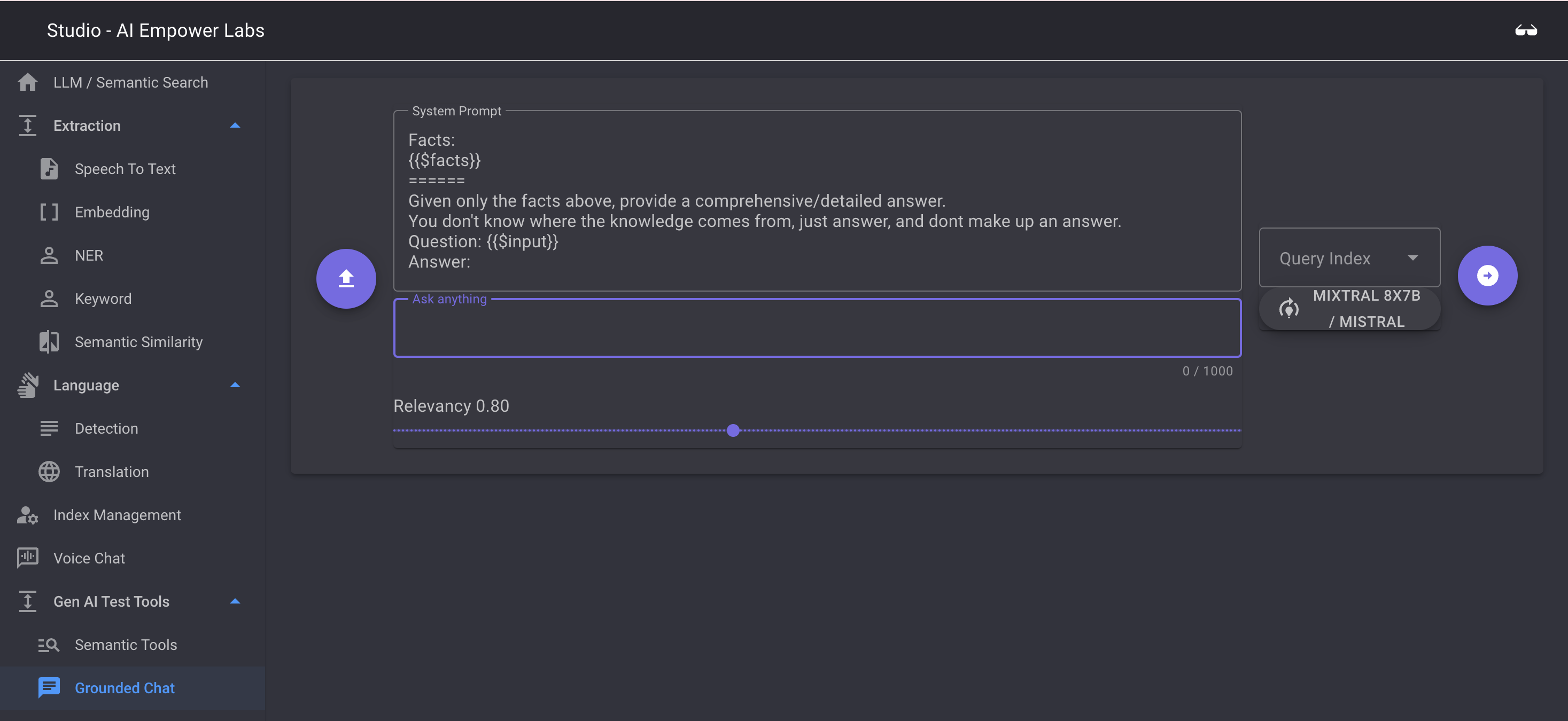 Grounded chat is a test tool for conversational chat towards the uploaded indexes. Here you can check the performance of your data in a conversational LLM driven format and check what accuracy is needed to achieve the best results
Grounded chat is a test tool for conversational chat towards the uploaded indexes. Here you can check the performance of your data in a conversational LLM driven format and check what accuracy is needed to achieve the best results
The Grounded chat conversational test tool use your indexes, the semantic search engine, the embedding storage and send the results from the index search to the selected LLM to generate a conversational reply to your ask
First use the System Prompt to set the prompt, the {{$facts}} in the default prompt, will be the results from the semantic search. The others tell the LLM to only use the facts from the Semantic search to build a reply.
Select the index you want to base the answer on in the Query Index select field.
If you do not _specify a languag_e to be used in the reply the LLM will return the answer in English even if you ask in another language.
If you want to control the Reply language add this to the prompt. Example "please answer me in Swedish", see figure below:
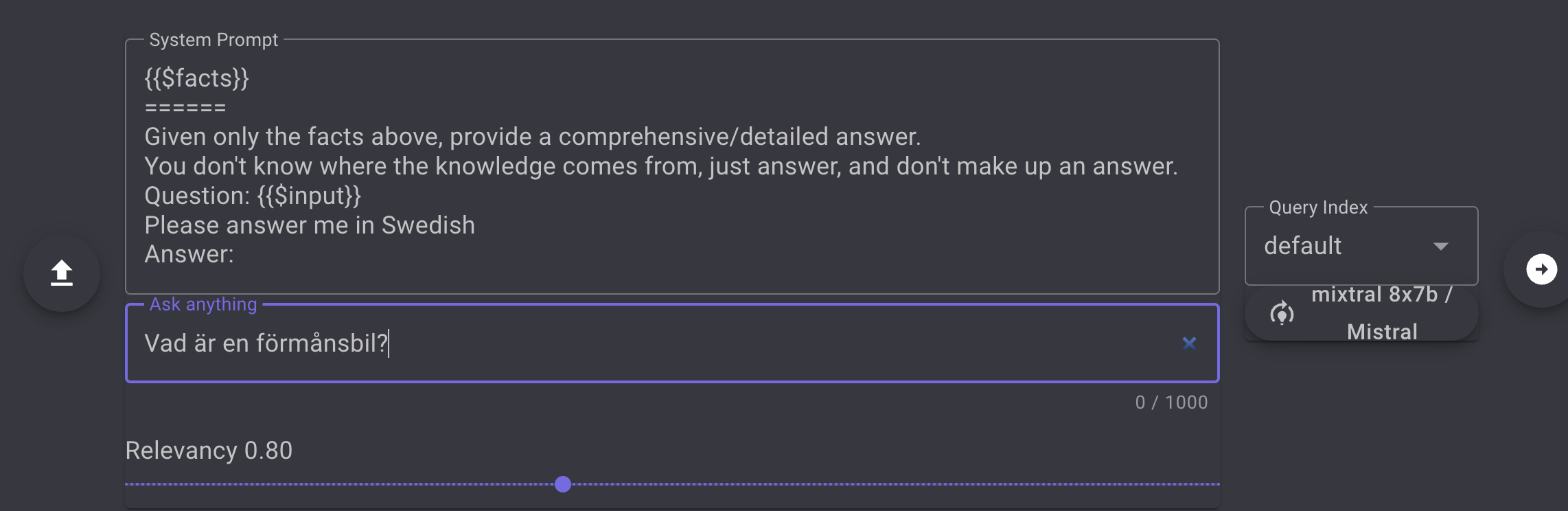
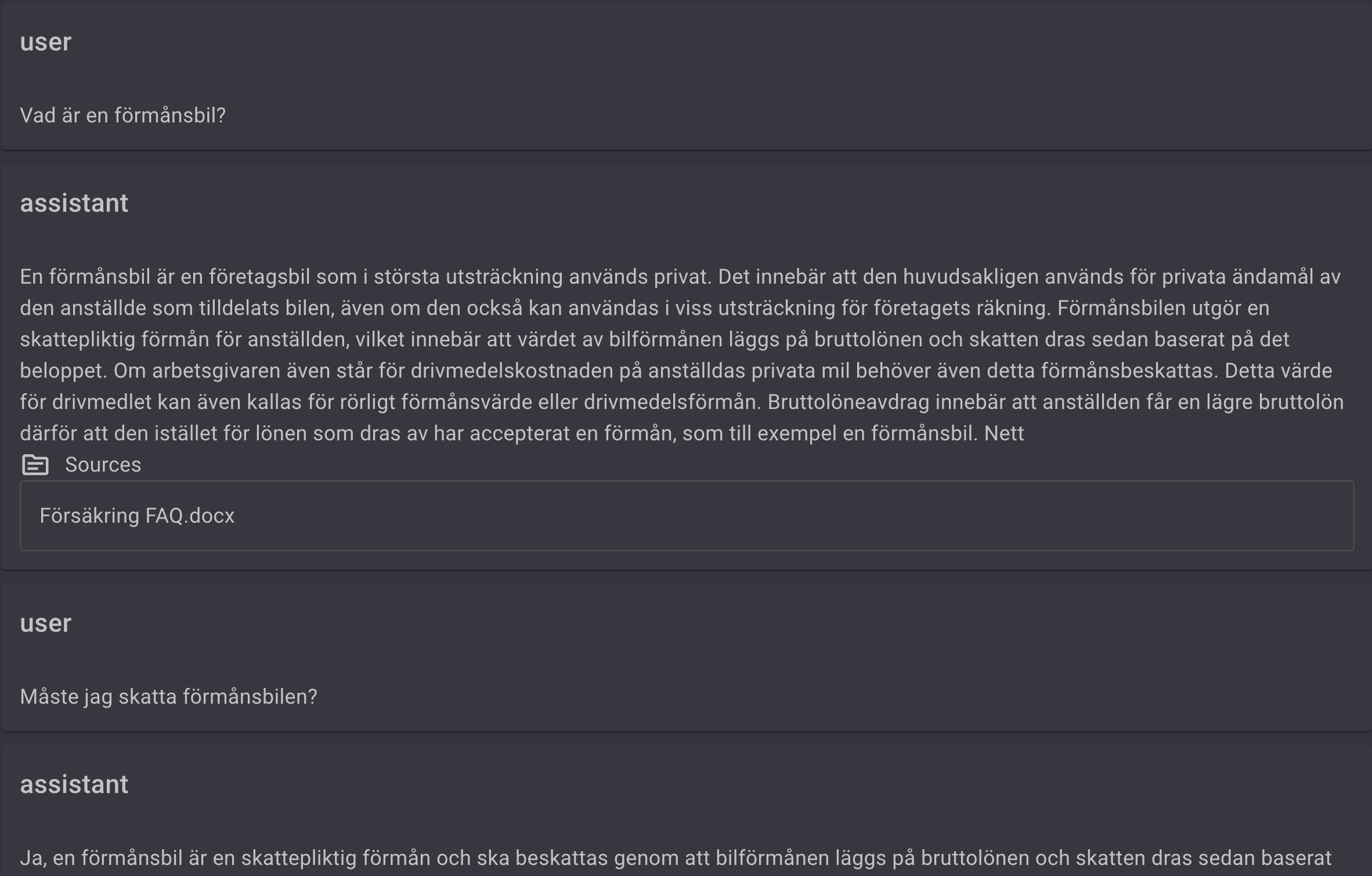
The response will be in a converational format and you are able to ask followup questions using the UI
This enables you to test using your index in a Virtual Assistant scenario where you combine the power of the semantic search and embedding system with the power of an LLM to conduct a conversation.
Language
Detection

Detection is a library to extract a langauge from text. This is a test to to check how good the language detection functionality in AI Empowerment Labs software works. It can also be used as a separate function to detect language from a string. The functionality is avaiable as a test application in the Studio, however the most common use case for this will be API calls to determine the language from incoming text to control applications that are language specific.
Translation
Translation provides the ability to translate from one language to another. The quality of the translation is the same as a human service, however some prompt tuning can be suitable in customer use cases. The ui is a sample of what can be also be achieved using the AI Empower Lab APIs
Extraction
Extraction is a grouping level of all extraction focused front end applications provided.
Speech-to-text
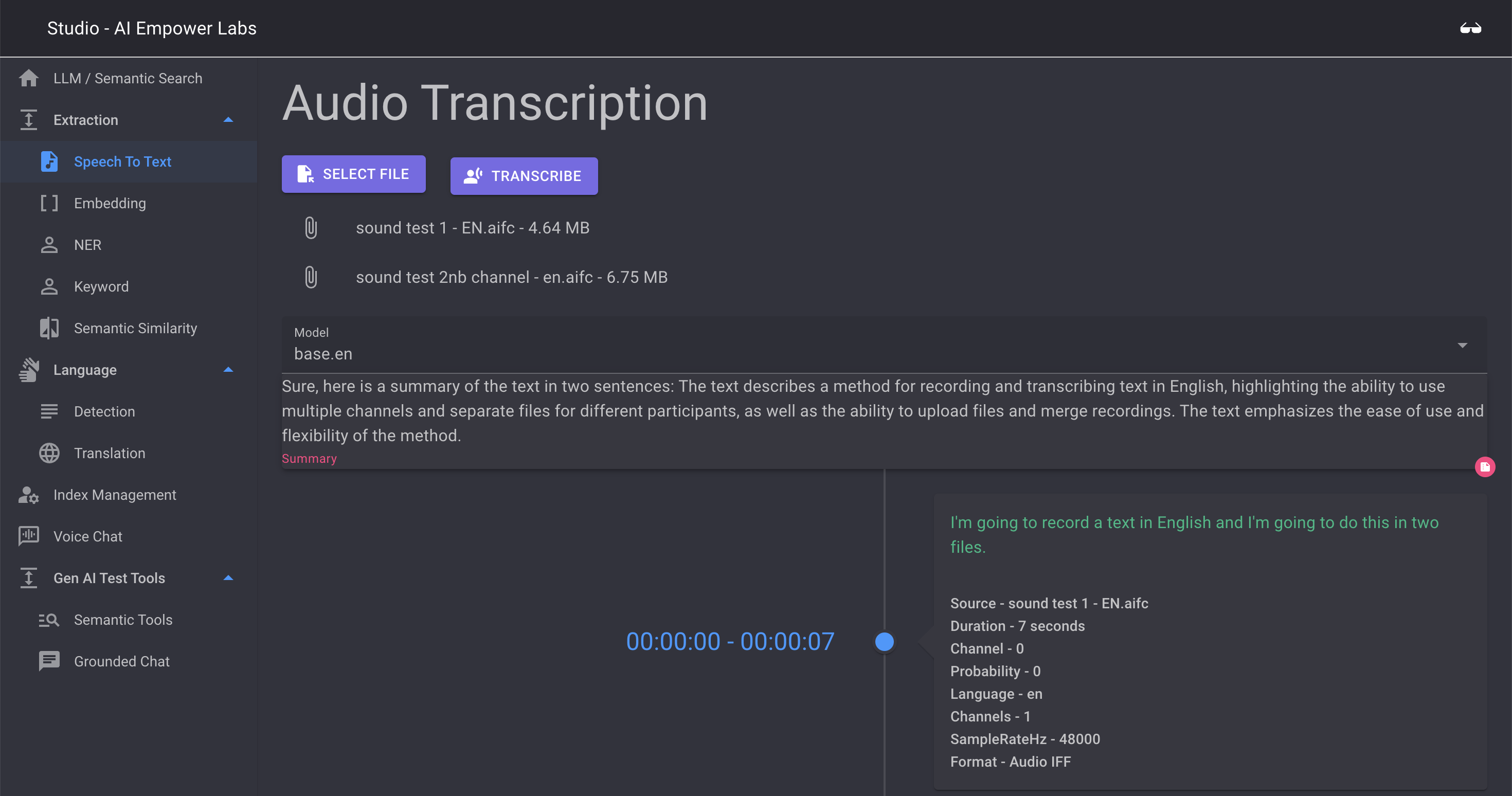
Speech to text is AI Empowerlabs implementation of AI driven Whisper based Speech-to-text. You can select one or more files and then perform an extraction of the text from these files. When extraction is completed the transcript with timestamps will appear When more than one file is selected the transcript will shown the two files in the same timeline. This means that the UI will assume that the two files are different audio channels from the same conversation. Where one contains the audio from speaker1 and another contains the audio sound from speaker2 etc.
Embedding
 Embedding is a test bed for experts to see how the embedding of text strings in uploaded documents and sound files will be processed and stored in the included embedding database. When using AI Empower Labs you will not need to buy expensive additional services from Embedding database vendors to0 be able to create grounded generative AI solutions. We incluce the Embedding algoritm and an optimized storage system for the embeddings
Embedding is a test bed for experts to see how the embedding of text strings in uploaded documents and sound files will be processed and stored in the included embedding database. When using AI Empower Labs you will not need to buy expensive additional services from Embedding database vendors to0 be able to create grounded generative AI solutions. We incluce the Embedding algoritm and an optimized storage system for the embeddings
Enter a text, select the Embedding version you want to test and see how the embeddings are created
NER (Named Entity Recognition)
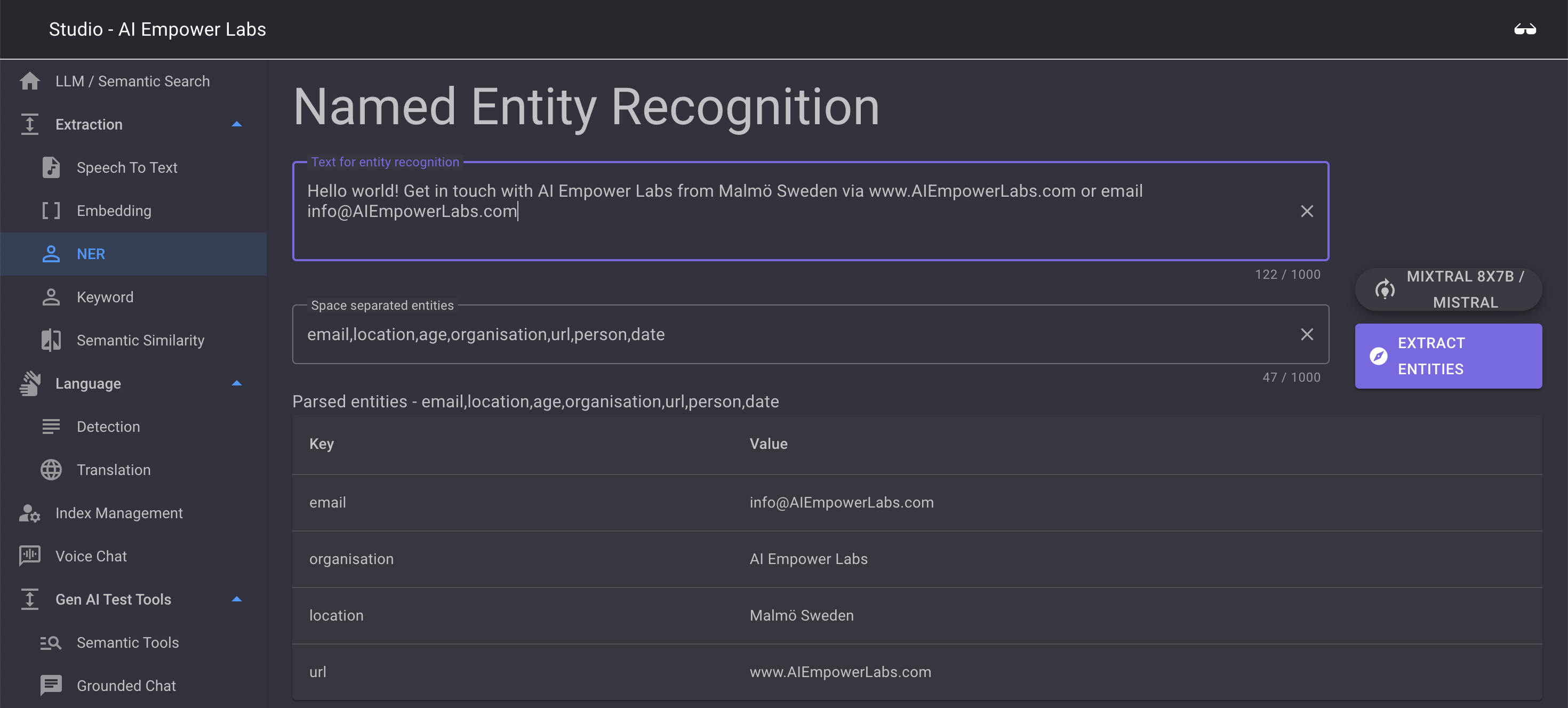 NER is a tool to expose the power of the AI Empower Labs API. A common use case to Gen AI is to extract entities from conversations that can be used to conduct busines transations in the AI system
NER is a tool to expose the power of the AI Empower Labs API. A common use case to Gen AI is to extract entities from conversations that can be used to conduct busines transations in the AI system
NER is based on the API and will look for a configurable array of entities in the provided text string
The tool is loaded with demo data.
To use the tool just press "extract entities" to extract entities from the provided demo text
The API can be used in many languages, the test tool is set up for English
Next change the entity list to something that suits you, for example "Name City"
then provide a sentence or a string contain text that have this entity in it to test if the NER system captures your entity
Example text sentence: "My name is Jaques and a I live in Paris, France"
A very powerful function considering that you to not need to teach the system what is the concept of a name and a city. You can in theory use any imaginable concept to capture this. However this concept need to be understood by the large langage model (true for most) or added to the model by adding your own data describing non standard entities valid for your business as a context to the LLM
Keyword extraction
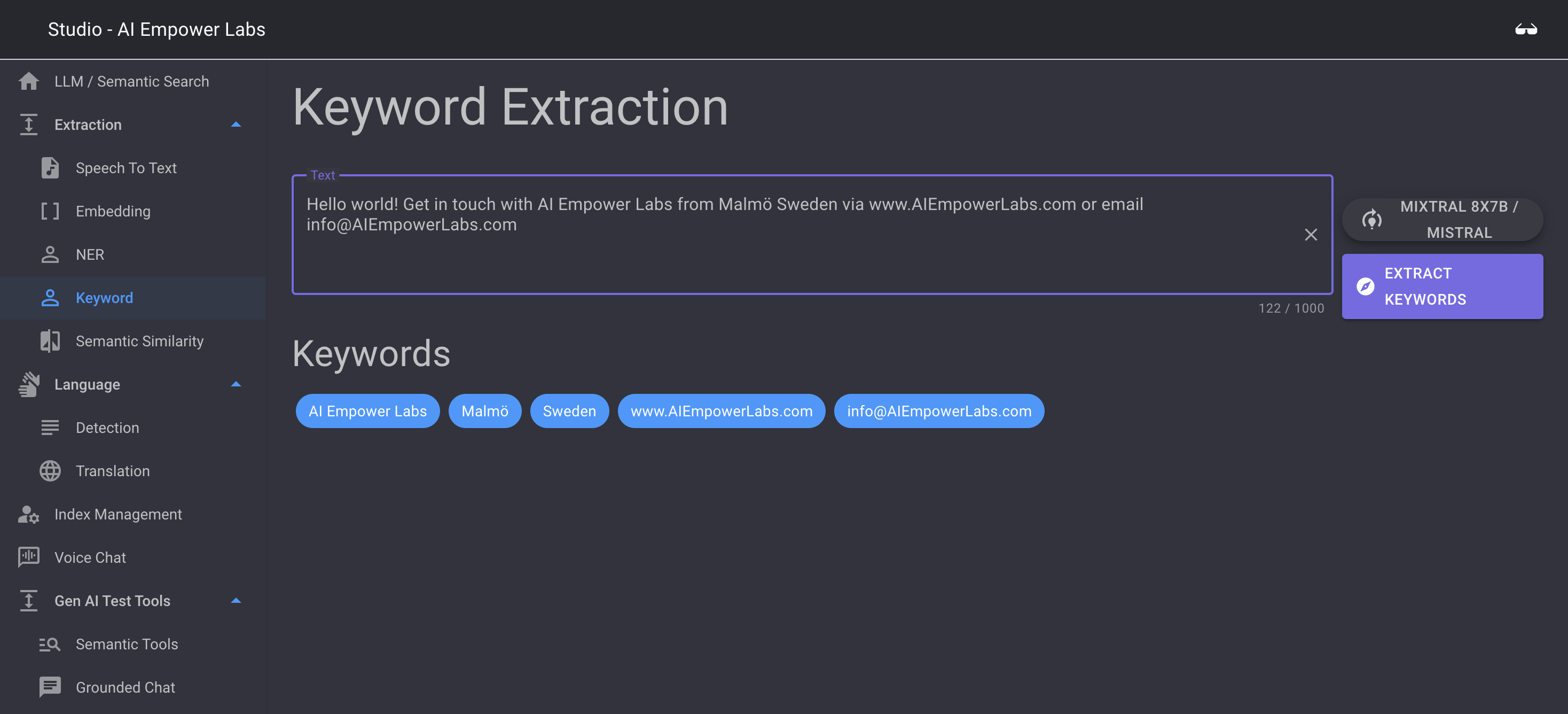 Keyword extraction extracts keywords from a text, much like a human would do when trying to extract this from a text. you can select what LLM you want to base the Keyword extraction on
Keyword extraction extracts keywords from a text, much like a human would do when trying to extract this from a text. you can select what LLM you want to base the Keyword extraction on
Semantic Similarity
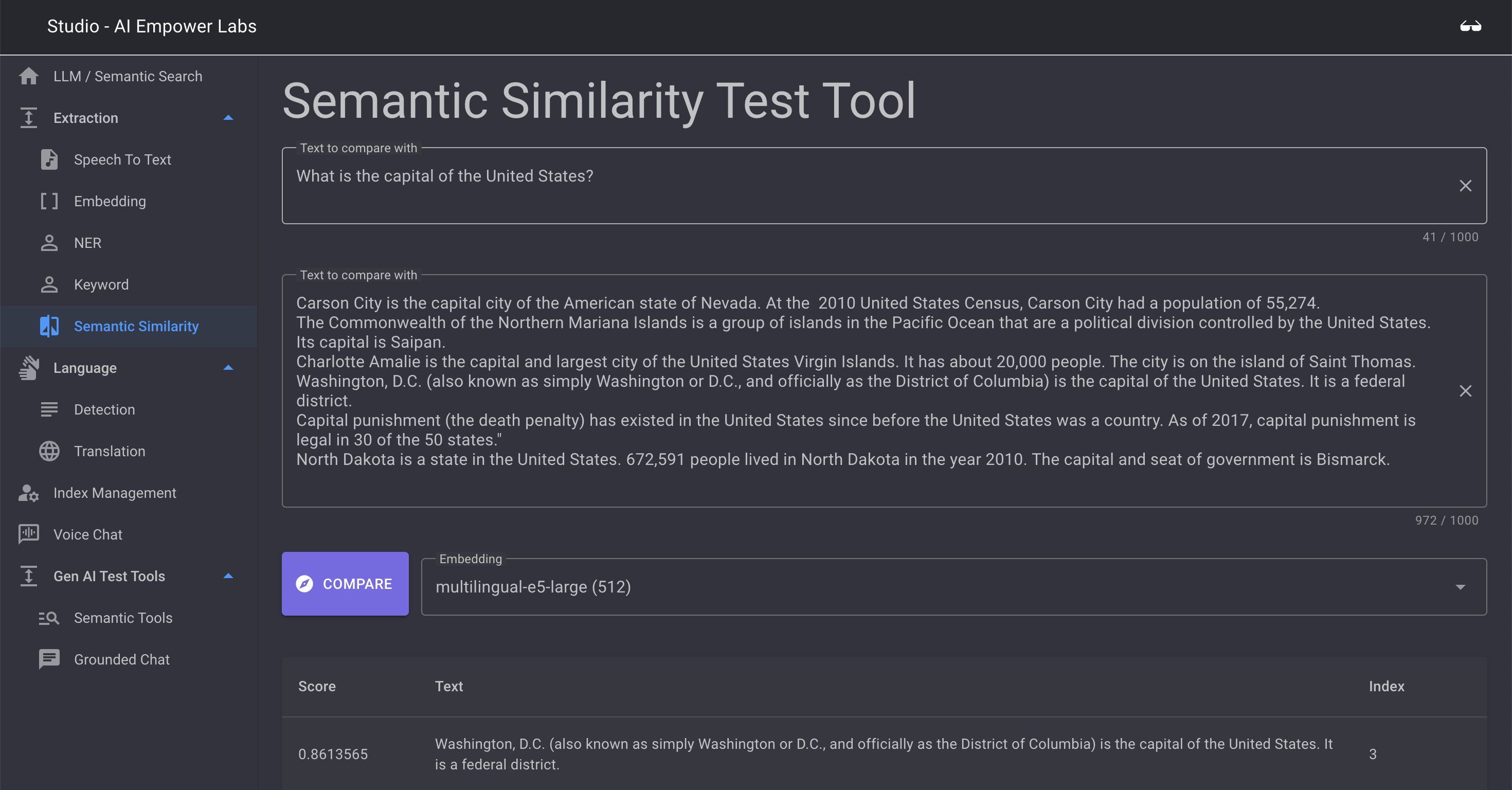
Semantic Similarity is a test to expose the power of the Semantic engine in AI Empower Labs software.
Here you can compare a string to another and find similarities
Study the default example to see the power of the semantic similary. Here you will see how the first sentence is matched to a number of matches in the 2nd text block and the score of matching
Using OpenAPI
Every container have API is OpenAPI and Swagger formats.
See included documentation in our OpenAPI compatiple API for usage and test cases.
Using Swagger API
Coming soon...
See the Swagger API included documentation for now
Getting Started
Chat Copilot Sample Application
This sample allows you to build your own integrated large language model (LLM) chat copilot. The sample is built on Microsoft Semantic Kernel and has three components:
- A frontend React web application
- A backend .NET REST API service
- A .NET worker service for processing semantic memory
These quick-start instructions run the sample locally. Extensive documentation can also be found on the official Chat Copilot Microsoft Learn documentation page for getting started.
AI Empower Labs has extended Microsoft's code to support our on-premise Generative AI LLM and RAG containers. Further extensions by AI Empower Labs enable LLM autotooling and function calling with any LLM, not just OpenAI LLMs. These enhancements have been embedded in our extended version of the Copilot.
To deploy the sample to Azure, please view the "Deploying Chat Copilot" section after meeting the requirements described below.
What is in the Package
The Co-pilot is a ready-to-go sample front-end application adapted for AI Empower Labs backend containers. The sample implements a co-pilot application and can be used with AI Empower Labs' innovation on LLM Autotooling to enable function call AI applications and provide a user-friendly interface.
Getting Started with the Public Shared CoPilot Version
You can access the public shared version online and download a copy using the instructions in AI Empower Labs' public open-source GitHub Studio/Co-pilot.
Instructions on how to install the Copilot applications are found there. You can then build your own version, deploy it to a Docker or Kubernetes server, and adjust the appsettings.json files.
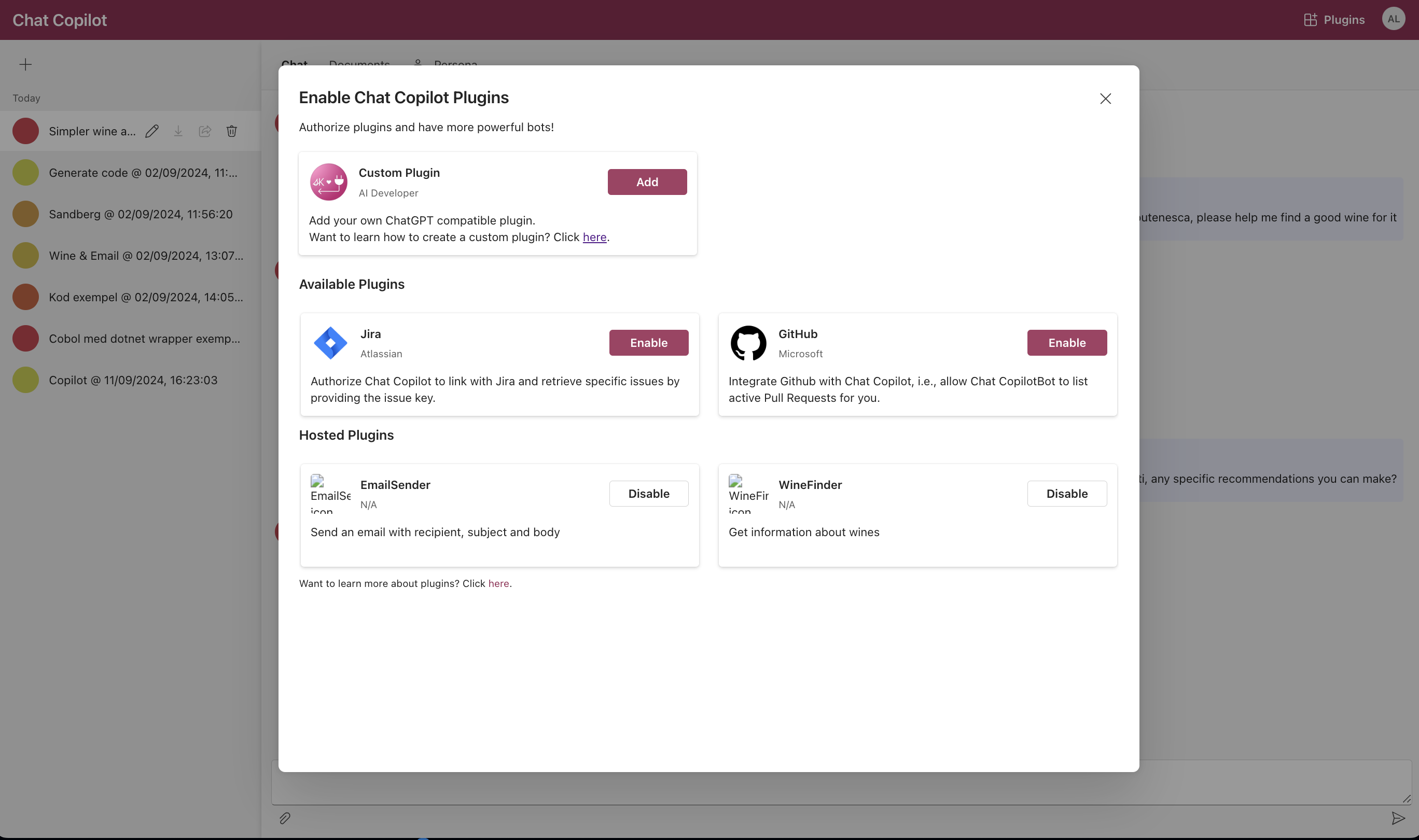
The Copilot comes with a couple of sample plugins to illustrate the powerful autotooling capabilities. These can be downloaded separately and activated in the plugin. There are two sample plugins: a web searcher, allowing the LLM to extend itself by searching the internet, and an email sender, a sample API calling application enabling the Copilot to send emails as part of the service it provides.
AI Empower Labs CoPilot Plugins
AI Empower Labs' version of CoPilot comes with some sample plugins. These plugins make use of the LLM autotooling and function calling concept that enables AI to perform actions. We have added a couple of sample plugins in the open-source application to demonstrate the powerful capabilities of our CoPilot.
Sample Plugins
-
Email Sender Plugin: This plugin enables the CoPilot to send emails as part of the service it provides. It showcases how the CoPilot can perform API calls to external services, making it a versatile tool for various applications.
-
Virtual Sommelier Plugin: This is a sample application that enables AI to understand and call an API for a wine shop. The CoPilot can act as a virtual sommelier, understanding what products are available and recommending them from the local store. This plugin demonstrates the possibilities of creating AI workers that are context-aware and company-aware, adhering to company limitations and policies while working.
These sample plugins illustrate the potential of AI Empower Labs' CoPilot to create AI workers that can perform specific tasks within the constraints of a given context, ensuring compliance with company policies and limitations.
Studio clients
Arbyte integration
Webscraper
FAQ & Terminology
FAQ
What is Generative AI or Gen AI
A Generative AI system is a type of artificial intelligence designed to create content. Unlike discriminative models that classify input data into categories, generative models can generate new data instances that resemble the training data. These systems can produce a wide range of outputs, including text, images, music, voice, and even synthetic data for training other AI models. Here's an overview of its key aspects:
How it Works: Generative AI systems often use advanced machine learning techniques such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformer models. In a GAN, for example, two networks are trained simultaneously: a generative network that creates data and a discriminative network that evaluates it. The generative network learns to produce more authentic outputs through this competition.
Applications: At AI Empower Labs we are currently focused on:
- Text Generation: Creating realistic and coherent text for articles, stories, code, or conversational agents.
- Image and Art Creation: Generating images, art, or photorealistic scenes from descriptions or modifying existing images in novel ways.
- Text to speech and speech to text: Using AI to extract text from voice data
What is RAG
Retrieval-Augmented Generation (RAG) combines the powers of pre-trained language models with a retrieval system to enhance the generation of text. This method retrieves documents relevant to a query and then uses this contextual information to generate responses. It's especially useful in tasks where having additional context or external knowledge can significantly improve the quality or accuracy of the output, such as in question answering, content creation, and more complex conversational AI systems.
Here's a breakdown of RAG features:
- Retrieval Component: At its core, RAG uses a retrieval system (like a search engine) to find documents that are relevant to the input query. This retrieval is typically performed using a dense vector space, where both queries and documents are embedded into vectors in a high-dimensional space. The system then searches for the nearest document vectors to the query vector.
- Augmentation of Pre-trained Models: RAG leverages pre-trained language models (like those from the GPT or BERT families) by feeding the retrieved documents into these models as additional context. This way, the generation is informed by both the input query and the retrieved documents, allowing for responses that are not only contextually relevant but also enriched with external knowledge.
- Flexible Integration: The RAG architecture can be integrated with different types of language models and retrieval mechanisms, making it highly versatile. Whether you're using a transformer-based model for generation or a different vector space model for retrieval, RAG can accommodate various setups.
- Improved Accuracy and Relevance: By incorporating external information, RAG models can produce more accurate and relevant responses, especially for questions or tasks that require specific knowledge not contained within the pre-trained model itself.
- Scalability and Efficiency: Despite its complex capabilities, RAG is designed to be scalable and efficient. It uses techniques like batched retrieval and caching to minimize the computational overhead of accessing external documents.
- End-to-End Training: RAG models can be fine-tuned end-to-end, allowing the retrieval and generation components to be optimized jointly. This leads to better alignment between the retrieved documents and the generated text, improving overall performance.
RAG represents a significant step forward in the field of natural language processing and generation, offering a way to create more informed, knowledgeable, and contextually relevant AI systems.
What is a container?
A container refers to a lightweight, standalone, and executable software package that includes everything needed to run a piece of software, including the code, runtime environment, libraries, and system tools. Containers encapsulate the application's code and its dependencies, making it easy to deploy, run, and scale applications consistently across different environments.
I am using Kubernetes in my Data Centre, is containers a good concept for me?
In the context of Kubernetes, containers are the smallest deployable units that can be created, scheduled, and managed. Kubernetes manages containers through Pods, which are the atomic unit of scheduling in Kubernetes. A Pod represents one or more containers that are deployed together on the same host and can share resources. Each container in a Pod runs in its isolated environment but can communicate with other containers in the same Pod as well as containers in other Pods across the Kubernetes cluster.
The use of containers in Kubernetes enables a microservices architecture, where applications are divided into smaller, independent parts that can be developed, deployed, and scaled independently. This approach facilitates continuous integration and delivery (CI/CD), improves resource utilization, and enhances the resilience and scalability of applications. Containers in Kubernetes are typically managed using container runtimes such as Docker, containerd, or CRI-O.
What is an LLM
A Large Language Model (LLM), like the one you're interacting with now, is an advanced artificial intelligence system designed to understand, generate, and interact with human language at a large scale. These models are based on a type of neural network architecture known as Transformer, which allows them to process and predict sequences of text efficiently. Here are some key points about Large Language Models:
-
Training Data and Process: LLMs are trained on vast datasets consisting of text from the internet, books, articles, and other language sources. The training process involves teaching the model to predict the next word in a sentence given the words that precede it. Through this, the model learns language patterns, grammar, semantics, and even some knowledge about the world.
-
Capabilities: Once trained, these models can perform a wide range of language-related tasks without needing task-specific training. This includes answering questions, writing essays, translating languages, summarizing texts, generating code, and engaging in conversation. Their flexibility makes them valuable tools in fields ranging from customer service and education to software development.
-
Examples: OpenAI's GPT (Generative Pre-trained Transformer) series, including GPT-3 and its successors, are prominent examples of Large Language Models. There are also other models like BERT (Bidirectional Encoder Representations from Transformers) by Google, which is optimized for understanding the context of words in search queries.
-
Challenges and Ethical Considerations: While LLMs are powerful, they also present challenges such as potential biases in the training data, privacy concerns, the propagation of misinformation, and the need for significant computational resources for training and deployment. Ethical use and ongoing research into mitigating these issues are crucial aspects of the development and deployment of these models.
-
Evolution and Future: LLMs continue to evolve, becoming more sophisticated with each iteration. This includes improvements in understanding context, generating more coherent and contextually relevant responses, and reducing biases. Future developments are likely to focus on making these models more efficient, ethical, and capable of understanding and generating language even more like a human.
What is Semantic Search
Semantic search in the context of Large Language models and RAG can be describes as these parts:
Retriever: This component is responsible for fetching relevant documents or passages from a large dataset (like Wikipedia) based on the query's semantic content. It doesn't just look for exact matches of query terms but tries to understand the query's intent and context. Techniques like Dense Vector Search are often used, where queries and documents are embedded into high-dimensional vectors that represent their meanings.
Answer Generator: This part, typically an LLM, takes the context provided by the retriever and generates a coherent and contextually appropriate answer. The generator can infer and synthesize information from the retrieved documents, leveraging its own trained understanding of language and the world.
LLMs, through their vast training on diverse textual data, inherently support semantic search by understanding and generating responses based on the meaning of the text rather than just the presence of specific words or phrases. When used in a semantic search:
Understanding Context: They can understand the nuanced meaning of queries, including idiomatic expressions, synonyms, and related concepts, allowing them to retrieve or generate more accurate and relevant responses.
Generating Responses: They can provide answers that are not just based on the most common responses but are tailored to the specific context and meaning of the query, often synthesizing information from various parts of their training data.
In essence, semantic search in the context of RAG and LLMs is about understanding and responding to queries in a way that mimics human-like comprehension, leveraging both the vast information available in external datasets and the deep, nuanced understanding of language encoded in the models. This approach enables more accurate, relevant, and context-aware answers to complex queries.
What in an Embedding, and why is this relevant for Generative AI systems?
In the context of artificial intelligence and natural language processing (NLP), an embedding is a representation of data, usually text, in a form that computers can understand and process efficiently. Essentially, embeddings convert words, phrases, sentences, or even entire documents into vectors of real numbers. These vectors capture semantic meanings, relationships, and the context in which words or phrases appear, enabling machines to understand and perform tasks with natural language.
Key Points About Embeddings:
-
Dimensionality: Embeddings are typically represented as high-dimensional vectors (often hundreds or thousands of dimensions) in a continuous vector space. Despite the high dimensionality, embeddings are designed to be efficient for computers to process.
-
Semantic Similarity: Words or phrases that are semantically similar tend to be closer to each other in the embedding space. This allows AI models to understand synonyms, context, and even nuances of language.
-
Usage in AI Models: Embeddings are foundational in various NLP tasks and models, including sentiment analysis, text classification, machine translation, and more. They allow models to process text data and perform tasks that require understanding of natural language.
-
Types of Embeddings:
- Word Embeddings: Represent individual words or tokens. Examples include Word2Vec, GloVe, and FastText.
- Sentence or Phrase Embeddings: Represent larger chunks of text, capturing the meaning of phrases or entire sentences.
- Document Embeddings: Represent whole documents, capturing the overall topic or sentiment.
-
Training Embeddings: Embeddings can be pre-trained on large text corpora and then used in specific tasks, or they can be trained from scratch as part of a specific AI model's training process.
Example:
Consider the words "king," "queen," "man," and "woman." In a well-trained embedding space, the vector representing "king" minus the vector representing "man" would be similar to the vector representing "queen" minus the vector representing "woman." This illustrates how embeddings capture not just word meanings but relationships between words.
Embeddings are a critical technology in the field of AI, enabling models to deal with the complexity and richness of human language by translating it into a mathematical form that algorithms can work with effectively.
What is Named Entity Recognition?
Named Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. NER is a fundamental step for a range of natural language processing (NLP) tasks like question answering, text summarization, and relationship extraction, providing a deeper understanding of the content of the text by highlighting its key elements.
Here's a closer look at its components and applications:
Named Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. NER is a fundamental step for a range of natural language processing (NLP) tasks like question answering, text summarization, and relationship extraction, providing a deeper understanding of the content of the text by highlighting its key elements.
Here's a closer look at its components and applications:
Components of NER
- Identification of Named Entities: The primary step is to identify the boundaries of named entities in text. This involves distinguishing between general words and those that represent specific entities.
- Classification of Entities: After identifying the entities, the next step is to classify them into predefined categories such as person names, organizations, locations, dates, etc.
- Contextual Analysis: NER systems often require an understanding of the context in which an entity is mentioned to accurately classify it. For example, distinguishing between "Jordan" the country and "Jordan" a person's name.
Techniques Used in NER
- Rule-based Approaches: These rely on handcrafted rules based on linguistic patterns. For instance, capitalization might be used to identify proper names, while patterns in the text can help identify dates or locations.
- Statistical Models: These include machine learning models that learn from annotated training data. Traditional models like Hidden Markov Models (HMMs), Decision Trees, and Support Vector Machines (SVMs) have been used for NER tasks.
- Deep Learning Models: More recently, deep learning approaches, especially those based on Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers, have been employed for NER, often achieving superior results by learning complex patterns from large datasets.
Applications of NER
- Information Retrieval: Improving search algorithms by focusing on entities rather than mere keywords.
- Content Recommendation: Recommending articles, products, or services based on the entities mentioned in content a user has previously shown interest in.
- Customer Support: Automatically identifying important information in customer queries to assist in quicker resolution.
- Compliance Monitoring: Identifying sensitive or regulated information in communications or documents.
- Knowledge Graph Construction: Extracting entities and their relationships to build knowledge bases for various domains.
NER is a crucial component in the toolkit of natural language processing, enabling machines to understand and process human languages in a way that is meaningful and useful for a wide array of applications.
What is Semantic Similarity and the relevancy for this in Generative AI
Semantic similarity in the context of Generative AI (Gen AI) refers to the measure of likeness between two pieces of text based on the meaning they convey, rather than their superficial characteristics or syntactic similarity. This concept is crucial in various natural language processing (NLP) tasks and applications within Generative AI, enabling these systems to understand, generate, and manipulate language in ways that align more closely with human understanding and use of language.
How it Works
- Vector Space Models: One common approach to assess semantic similarity involves representing text as vectors in a high-dimensional space (using techniques such as TF-IDF, word embeddings like Word2Vec, GloVe, or contextual embeddings from models like BERT). The semantic similarity between texts can then be quantified using distance or similarity metrics (e.g., cosine similarity) in this space, where closer vectors represent more semantically similar content.
- Transformer Models: Modern Generative AI systems, especially those based on transformer architectures, inherently learn to encode semantic information in their representations. These models, through self-attention mechanisms, are adept at capturing nuanced semantic relationships within and across texts, facilitating a deeper understanding of similarity based on context and meaning rather than just keyword matching.
Applications
- Text Generation: Semantic similarity measures can guide the generation of text that is contextually relevant and coherent with given input text, enhancing the quality of outputs in applications like chatbots, content creation tools, and summarization systems.
- Content Recommendation: By assessing the semantic similarity between documents, articles, or user queries and content in a database, systems can provide more relevant and meaningful recommendations to users.
- Information Retrieval: Enhancing search engines and databases to return results that are semantically relevant to the query, even if the exact words are not used, leading to more effective and intuitive search experiences.
- Question Answering and Conversational AI: Semantic similarity allows for the matching of user queries to potential answers or relevant information in a knowledge base, even when queries are phrased in varied ways, improving the performance of QA systems and conversational agents.
- Document Clustering and Classification: Grouping or classifying documents based on the semantic content enables more efficient information management and retrieval, useful in areas like legal document analysis, academic research, and content management systems.
Semantic similarity is a foundational concept in Generative AI, enabling these systems to interact with and process human language in a way that is both deeply meaningful and contextually nuanced. This capability is integral to creating AI that can effectively understand, communicate with, and serve the needs of humans in a wide range of applications.
How can Generative AI improve speech to text transcription?
Artificial Intelligence (AI) has significantly improved speech-to-text (STT) transcription technologies, making them more accurate, faster, and adaptable to various use cases and environments. Here are several key ways AI enhances speech-to-text transcriptions:
1. Increased Accuracy
- Contextual Understanding: AI algorithms can understand context and disambiguate words that sound similar but have different meanings based on their usage in a sentence. This context-aware transcription significantly reduces errors.
- Accent Recognition: AI models trained on diverse datasets can accurately transcribe speech from speakers with a wide range of accents, improving accessibility and user experience for a global audience.
2. Real-time Transcription
- AI enables real-time or near-real-time transcription, essential for live broadcasts, meetings, and customer service interactions. This immediate feedback is crucial for applications like live subtitling or real-time communication aids for the deaf and hard of hearing.
3. Learning and Adapting
- Continuous Learning: AI models can learn from their mistakes and adapt over time, improving accuracy with continued use. This learning process includes adapting to specific voices, terminologies, and even user corrections.
- Personalization: Speech-to-text systems can be personalized to recognize and accurately transcribe specific jargons, technical terms, or even user-specific colloquialisms, making them more effective for professional and industry-specific applications.
4. Noise Cancellation and Background Noise Management
- AI can distinguish between the speaker's voice and background noise, filtering out irrelevant sounds and focusing on the speech. This capability is particularly valuable in noisy environments, ensuring clear and accurate transcriptions.
5. Language and Dialect Support
- With AI, speech-to-text systems can support a broader range of languages and dialects, often underserved by traditional technologies. This inclusivity opens up technology access to more users worldwide.
6. Integration with Other AI Services
- Speech-to-text can be combined with other AI services like sentiment analysis, language translation, and chatbots to provide more comprehensive solutions. For example, transcribing customer service calls and analyzing them for sentiment can offer insights into customer satisfaction.
7. Cost-effectiveness and Scalability
- AI-driven systems can handle vast amounts of audio data efficiently, making speech-to-text services more cost-effective and scalable. This scalability allows for the transcription of large volumes of lectures, meetings, and media content that would be prohibitive with manual transcription services.
Future Directions
AI is also driving innovation in speech-to-text technologies through approaches like end-to-end deep learning models, which promise further improvements in accuracy, speed, and versatility. As AI technology continues to evolve, we can expect speech-to-text transcription to become even more integrated into our daily lives, enhancing accessibility, productivity, and communication.
What is prompt engineering
Prompt engineering is the process of designing and refining prompts that guide artificial intelligence (AI) models, like chatbots or image generators, to produce specific or desired outputs. This practice is especially relevant with models based on machine learning, including those trained on large datasets for natural language processing (NLP) or computer vision tasks. The goal is to communicate effectively with the AI, guiding it towards understanding the task at hand and generating accurate, relevant, or creative responses.
The skill in prompt engineering lies in how questions or commands are framed. The quality of the input significantly influences the quality of the output. This includes the choice of words, the structure of the prompt, the specificity of instructions, and the inclusion of any context or constraints that might help the model understand the request better.
Prompt engineering has become increasingly important with the rise of models like GPT (Generative Pre-trained Transformer) for text and DALL-E for images, where the ability to elicit precise or imaginative outputs from the model becomes a blend of art and science. It involves techniques like:
- Prompt Crafting: Writing clear, concise, and well-defined prompts that align closely with the task you want the AI to perform.
- Prompt Iteration: Experimenting with different formulations of a prompt to see which produces the best results.
- Zero-shot, Few-shot, and Many-shot Learning: Specifying the amount of guidance or examples provided to the AI. Zero-shot involves giving the AI a task without any examples, few-shot includes a few examples to guide the AI, and many-shot provides many examples to help the AI understand the context better.
- Chain of Thought Prompting: Providing a step-by-step explanation or reasoning path in the prompt to help the AI tackle more complex questions or tasks.
Effective prompt engineering can significantly enhance the performance of AI systems in various applications, such as content creation, data analysis, problem-solving, and customer service, making it a valuable skill in the AI and computer science fields.
Examples of prompt engineering commands
These examples will illustrate how different ways of asking or framing a question can lead to varied responses, showcasing the importance of clear and effective communication with AI systems.
1. Direct Command
- Basic Prompt: "Write a poem about the sea."
- Engineered Prompt: "Create a short, four-line poem in the style of a haiku about the peacefulness of the sea at sunset."
Explanation: The engineered prompt is more specific, not only requesting a poem about the sea but also specifying the style (haiku) and the theme (peacefulness at sunset), likely leading to a more focused and stylistically appropriate response.
2. Adding Context
- Basic Prompt: "Explain the theory of relativity."
- Engineered Prompt: "Explain the theory of relativity in simple terms for an 8-year-old, focusing on the concept of how fast things move through space and time."
Explanation: By adding context about the audience's age and focusing on key concepts, the engineered prompt guides the AI to tailor the complexity of its language and the aspects of the theory it discusses.
3. Request for Examples
- Basic Prompt: "What is machine learning?"
- Engineered Prompt: "What is machine learning? Provide three real-world examples of how it's used."
Explanation: This prompt not only asks for a definition but also explicitly requests examples, making the response more practical and illustrative.
4. Specifying Output Format
- Basic Prompt: "List of renewable energy sources."
- Engineered Prompt: "Generate a bullet-point list of five renewable energy sources, including a brief explanation for each."
Explanation: The engineered prompt specifies not only to list the sources but also to format the response as a bullet-point list with brief explanations, making the information more organized and digestible.
5. Encouraging Creativity
- Basic Prompt: "Story about a dragon."
- Engineered Prompt: "Write a captivating story about a friendly dragon who loves baking, set in a magical forest. Include dialogue and describe the setting vividly."
Explanation: The engineered prompt encourages creativity by adding details about the dragon's personality, setting, and including specific storytelling elements like dialogue and vivid descriptions.
6. Solving a Problem
- Basic Prompt: "How to fix a slow computer."
- Engineered Prompt: "List the top five reasons a computer might be running slowly and provide step-by-step solutions for each."
Explanation: This prompt not only asks for reasons behind a common problem but also guides the AI to structure the response in a helpful, step-by-step format, making it more actionable for the reader.
These examples illustrate the principle of prompt engineering: by carefully crafting your request, you can guide the AI to produce more precise, informative, or creative outputs. This is a crucial skill in fields that involve human-AI interaction, enhancing the effectiveness of AI tools for a wide range of applications.
Terminology
This section will describe AI Empower Labs terminology. Hopefully we will be able to comply to industry standards to the greatest possible extent and refrain from creating our own concepts as vendors like Microsoft (Cognitive Search) and OpenAI (GPTs) are doing :-)
Coming soon, but only if really needed ;-)...